07. Teoria dell'approssimazione
7. Teoria dell'approssimazione
La teoria dell'approssimazione è una branchia dell'analisi numerica utile ad approssimare una serie di dati con una funzione di qualche tipo.
Può essere divisa in due macroaree:
Si hanno delle misurazioni sperimentali dell'allungamento di una molla:
| 2 | 3 | 4 | ... | 10 | |
|---|---|---|---|---|---|
| 7.0 | 8.3 | 9.4 | ... | 15.9 |
Legge di Hooke:
type: line
labels: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
series:
- title: x
data: [3, 4.5, 7.0,8.3, 9.4, 10.2, 11.4 ,12.8, 14.0, 14.2,15.9 ]
tension: 0.2
width: 80%
labelColors: false
fill: false
beginAtZero: false
bestFit: true
bestFitTitle: undefined
bestFitNumber: 0Braccio robotico deve fare dei fori.
Dobbiamo comunicare:
- Posizione dei fori
- Percorso più breve
Uso polinomi a tratti di grado 3 (Spline)
Approssimazione ai minimi quadrati
Sia
Vogliamo minimizzare la distanza tra i dati e la funzione approssimante.
Calcolo la distanza come norma Euclidea: scarto quadratico
Voglio minimizzare lo scarto quadratico
Posso anche pesare i dati:
Possibili funzioni approssimanti
Retta
2 parametri incogniti:
Polinomi algebrici
Per fenomeni regolari dove non prevediamo grosse variazioni
Polinomi trigonometrici
Funzioni lineari logaritmiche
Funzioni esponenziali
Problema fondamentale
Dato il vettore
di
- nodi:
Lo [[#Scarto quadratico]] è
Le incognite sono i parametri
L'obiettivo è minimizzare rispetto ai parametri la funzione:
Procedo al calcolo della derivata:
Distribuendo la sommatoria, ottengo
da cui definisco una matrice
le cui entrate sono:
Posso quindi costruire la matrice
è definita positiva è regolare - Esiste una sola soluzione
Calcolo l'Hessiana
Rispetto alla derivata prima, i
è definita positiva
Polinomio Algebrico ai minimi quadrati
- Dati:
definisco il polinomio:
si ha quindi che
gli elementi della matrice
Termine noto:
Retta di regressione M = 1
[[#Polinomio Algebrico ai minimi quadrati]] di grado 1
si ha
dove
Retta di regressione:
Elementi matrice
Termine noto
Coefficienti:
Costruire la retta di regressione per le seguenti misurazioni:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | 6 | 8 | 10 | |
| 7.0 | 8.3 | 9.4 | 11.3 | 12.3 | 14.4 | 15.9 |
In questo caso
Calcolo
per cui:
Calcolo il termine noto:
Calcolo i parametri
type: line
labels: [2,3,4,5,6,8,10]
series:
- title: Forza
data: [7.0,8.3,9.4,11.3,12.3,14.4,15.9]
tension: 0.2
width: 80%
labelColors: false
fill: false
beginAtZero: false
bestFit: false
bestFitTitle: Retta di regressione
bestFitNumber: 0Approssimazione trigonometrica
Ha periodo
- Nodi:
- Passo:
La funzione approssimante è una funzione del tipo:
Dobbiamo determinare i coefficienti
Funzione approssimante:
Coefficienti:
Interpolazione
Un tipo di approssimazione tale che la funzione approssimante
dove
Interpolazione polinomiale
Siano assegnati i valori
Il problema dell'interpolazione polinomiale consiste nella determinazione di un polinomio di grado minimo che passi per i punti
Si ha che il generico polinomio di grado
Per la determinazione dei coefficienti ci si riduce al sistema:
dal quale otteniamo la matrice dei coefficienti (di questo sistema), detta matrice di Vandermonde:
Questa matrice, nella base dei monomi, può risultare mal condizionata. Si preferisce quindi usare una forma diversa del polinomio, i #Polinomi di base di Lagrange.
Polinomi di base di Lagrange
Si tratta di
ognuno dei quali soddisfa la seguente proprietà:
Per cui:
Si può a questo punto scrivere il polinomio interpolatore come:
In breve:
Costruisco i polinomi di Lagrange:
Scrivo il polinomio interpolatore come:
❗❗❗❗❗❗❗❗❗❗❗❗
❗❗❗ COMPLETARE ❗❗❗
❗❗❗❗❗❗❗❗❗❗❗❗
Errore di interpolazione
Nell'interpolazione ci sono 2 sorgenti di errore:
- #Errore di troncamento (interpolazione): quello dovuto alla sostituzione della funzione con un polinomio
- #Errore di propagazione (interpolazione): quello dovuto a un errore nei dati
Definito
e
definiamo l'errore di interpolazione come segue:
dove
Errore di troncamento Errore di propagazione
Per cui è ovvio che, dalla ##disuguaglianza triangolare
Errore di troncamento (interpolazione)
con
Dell'errore di troncamento, possiamo dare la seguente maggiorazione:
Errore di propagazione (interpolazione)
dove
l'errore sui dati è l' -esimo polinomio in base di Lagrange è la funzione di Lebesgue
ricordo:
Interpolazione trigonometrica
- Nodi:
Polinomio interpolatore trigonometrico
Coefficienti:
Interpolazione Spline
Partizione
La partizione
Funzione Spline
La funzione Spline di grado
è un polinomio di grado nei sotto-intervalli
Spline lineare
- Nodi:
La spline lineare interpolante è un polinomio a tratti continuo che soddisfa le condizioni di interpolazione
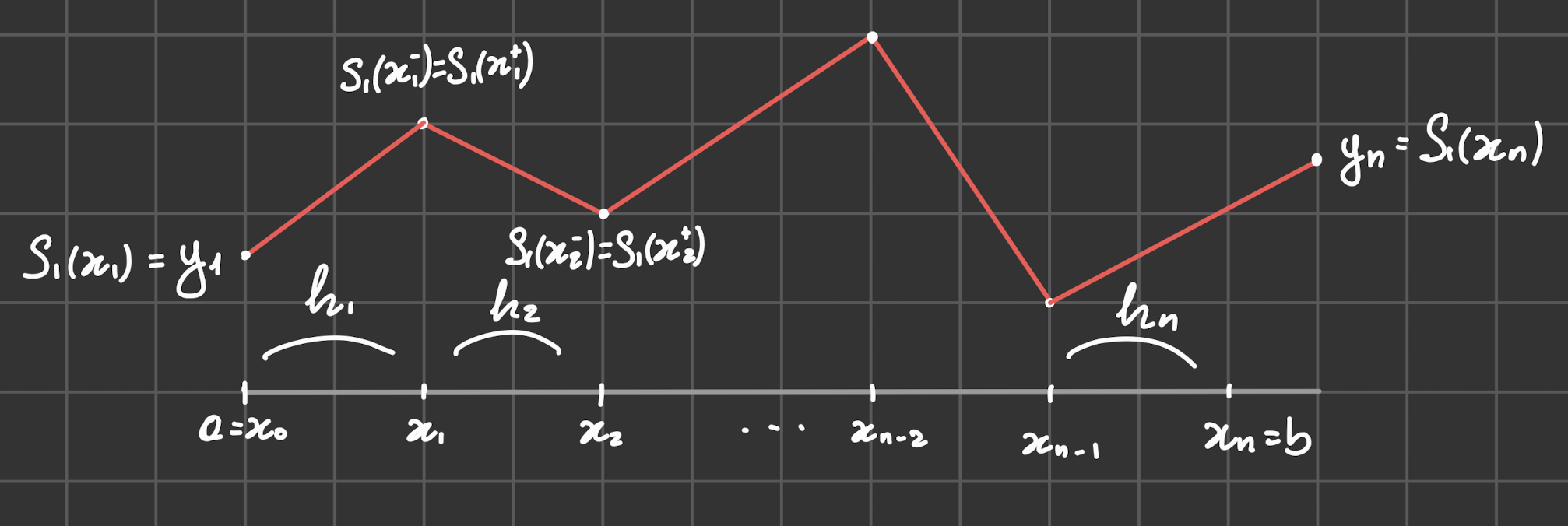
Spline lineare interpolante,
Base lagrangiana:
Per cui la spline lineare interpolante in base lagrangiana diventa: