04 - Trip Distribution Modeling - TDBM
04 - Trip Distribution Modeling - TDBM
Trip Distribution is the second step in the modeling stage of the classic 4 stage framework.
In terms of an O/D matrix like the following, in this step we try to model each and every
where:
number of trips from TAZ to TAZ tot number of trips generated by TAZ - It's the sum of the colums
tot number of trips attracted by TAZ - It's the sum of the rows
tot number of TAZs
Along this note, the number of trips from TAZ
Introduction
Trip distribution models are conceptually simple but give a hard time when we try to integrate them with the other models in the 4 stage process (for example, often, the sum of the number of trips from one zone does not add app to the modelled marginal total).
- Production (
) and attraction ( ) for each zone is known by purpose
Notation
Lower case letters indicate observations:
trips, trips originated, trips attracted
Uppe rcase letters represent values we are trying to model:
trips from to by mode and person type (population segment group) total number od trips originating at zone and attracted to zone , respectively
If a subscript or superscript is omitted, we are impying a summation over that index:
Key principles
Here we list some key principle of trip distribution models:
- Bigger TAZs produce/attract more trips
- Closer TAZs attract more trips
- Further TAZs attract less trips: we will consider a deterrence function (
where is the cost from TAZ to ).
Trip distribution models
- Demand origin-destination
- Beckmann & Golob:
- Wardrop:
- Beckmann & Golob:
- Choice
- Logit:
- Logit:
- Opportunity
- Of intervention...
- Of competence...
- #Gravity models
- [[#Entropy models]]
Gravity models
Gravity models are #Trip distribution models inspired by [[Newton's law of gravitational attraction]]
the model for gravitational attraction between two masses.
The basic gravity model is:
where:
a constant all trips generated from zone (= to marginal total ) all trips attracted to zone (= to marginal total ) generalized cost from zone to zone another parameter (if then we have exactly the same form of Newton's law)
Variations of this model exist:
As we can see, these models have several parameters that need to be calibrated. At first, this might look like a difficult task:
But, if we apply a logarithmic transformation on both sides, we can simply the calibration process:
As we can see, this has now become a simple linear model in the form:
that can be easily estimated as a linear regression model.
We considered
As anticipated before, the issue with these kind of models is that the sum of the estimated
but this often does not happen. When this is the case singly or doubly constrained [[#Growth factors]] must be applied.
In order to predict future demand, growth factors are usually used
Growth factors
- [[#Uniform growth factor]]
- #Singly constrained growth factor
- [[#Doubly constrained growth factor]]
Uniform growth factor
The uniform growth factor is a simple way to predict future trips. Given data for a base year, we simply apply a growth of a certain percentage to every O/D pair.
The following table shows the base year trips:
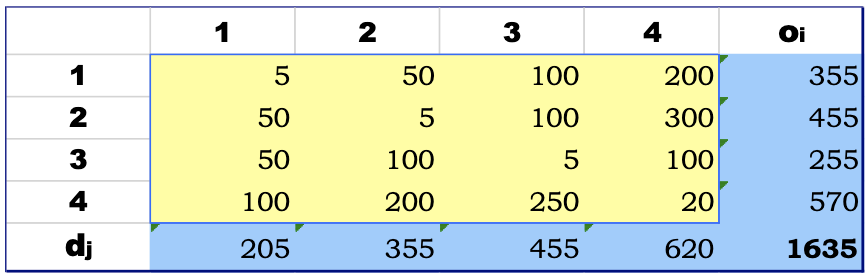
A growth factor of
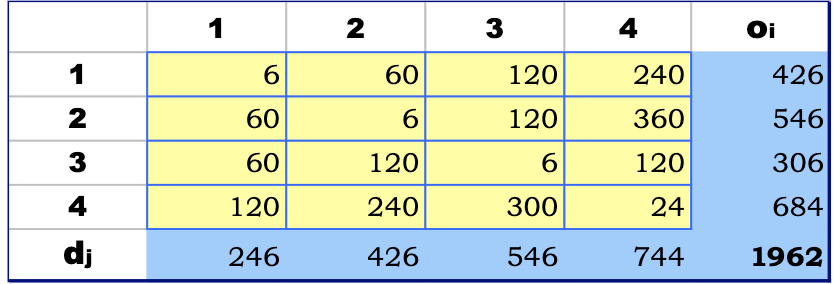
Singly constrained growth factor
The Singly constrained growth factor is used when marginal totals of either production or attraction are not equal to the sum of the corresponding
The following examples assumes that there is a difference in the origin totals (
The base OD matrix is shown:
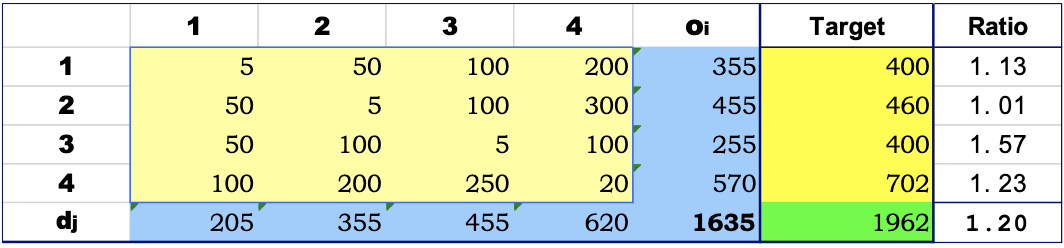
Notice how
Let
and we get:
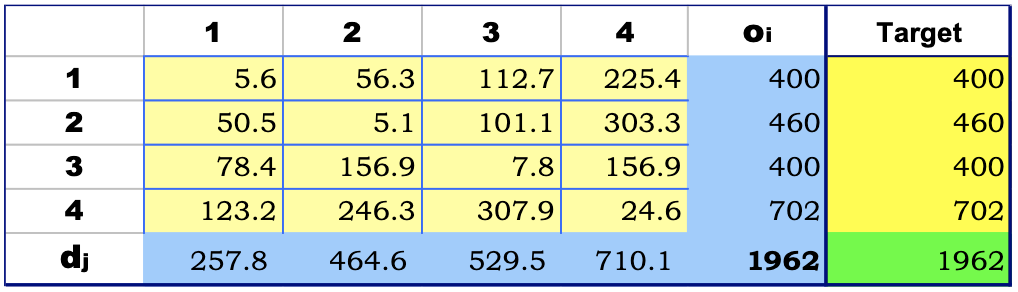
After the transformation we can see that
Since the
Doubly constrained growth factor - Biproportional Fitting (BPF)
The Doubly constrained growth factor is used when marginal totals of both production and attraction are not equal to the sum of the corresponding
This method is also known under the name: Bi-proportional fitting (BPF).
We start from the following base O/D matrix:
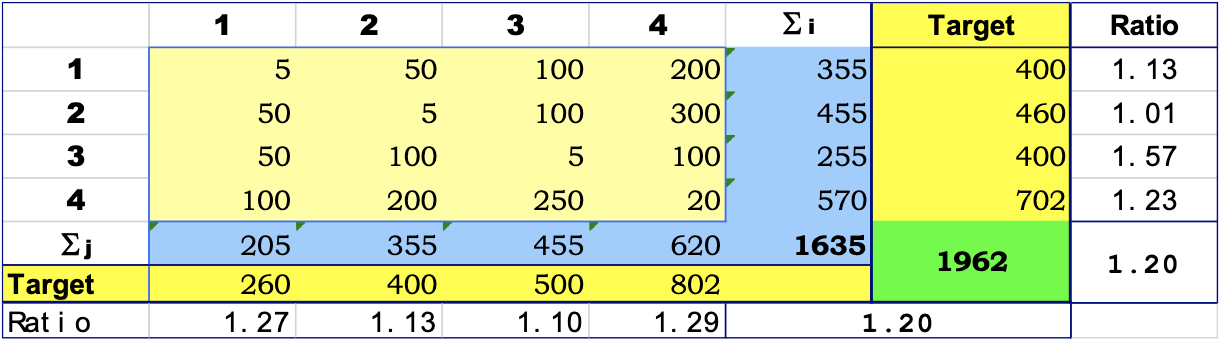
In this case there is not a direct method to obtain a single growth factor. The same process described in [[#Singly constrained growth factor]] is applied several time alternatively for Origins and destinations until we get acceptable ratios between the marginal totals and the targets.
- Calculate ratio for origins and apply it to every row
- Calculate ratio for attractions and apply it to every column
- Calculate ratio for origins and apply it to every row
- Calculate ratio for attractions and apply it to every column
- ... And so on
After not many iterations, we get a situation similar to that shown in the next table:
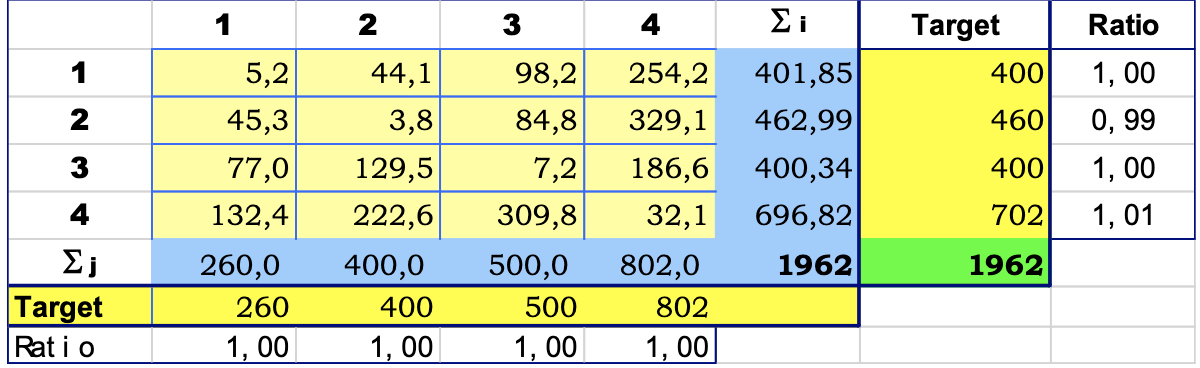
Limitations
Sparse matrices can cause problems when applying this method. If 0s are present, often the method will not converge. In this case, it is suggested to change these zeros to a low number of trips and try again.
Be careful though. It's important to distinguish between zeros by chance (sampling error) and structural zeros (there are some trips that cannot physically be made).
Synthetic distribution models
Synthetic distribution models are a kind of [[#Trip distribution models]] that generilize [[#Gravity models]] and try to bring more robust internal consistency. In their most general form:
where:
balancing factors ensuring trip-end constraints are met (so to obtain internally consistent models) a functional for the travel cost between zone and zone
Several functionals are proposed for the cost:
exponential function power function combined function (gamma) lognormal function top lognormal function
Notice how each of these functionals has one or more parameters that need to be calibrated. This is one of the main problems in applying this model.
Apply a synthetic distribution models
In this section we will see how to use #Synthetic distribution models to fill in the cells of an O/D matrix (calculate
We will describe the process for a general functional
We start from a cost matrix. This matrix contains the cost
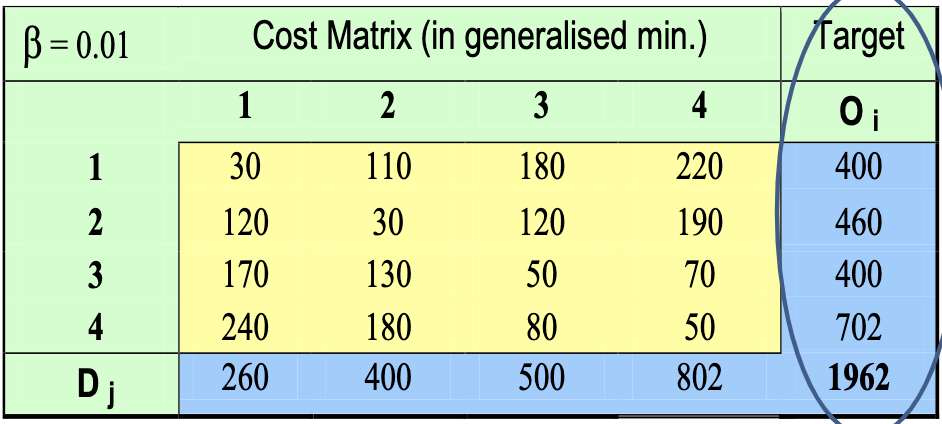
Now we apply the functional to the whole matrix: take any cell and calculate
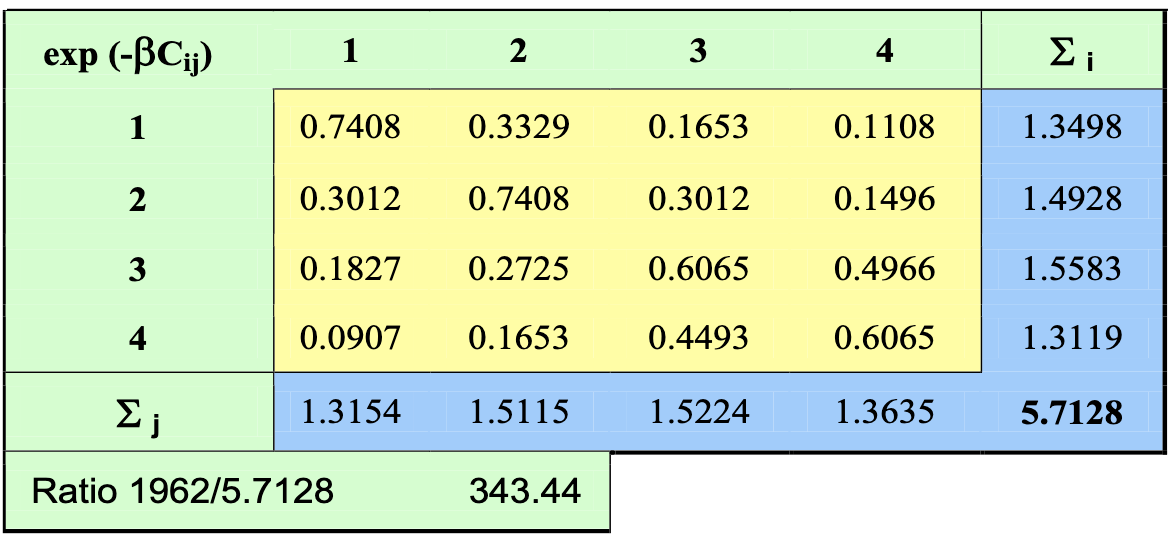
Now we need to apply the #Doubly constrained growth factor - Biproportional Fitting (BPF) method. To do so, we need a starting matrix containing trips. We can obtain it multiplying everything by an expansion factor calculated as:
In this case, it would be:
Yielding:
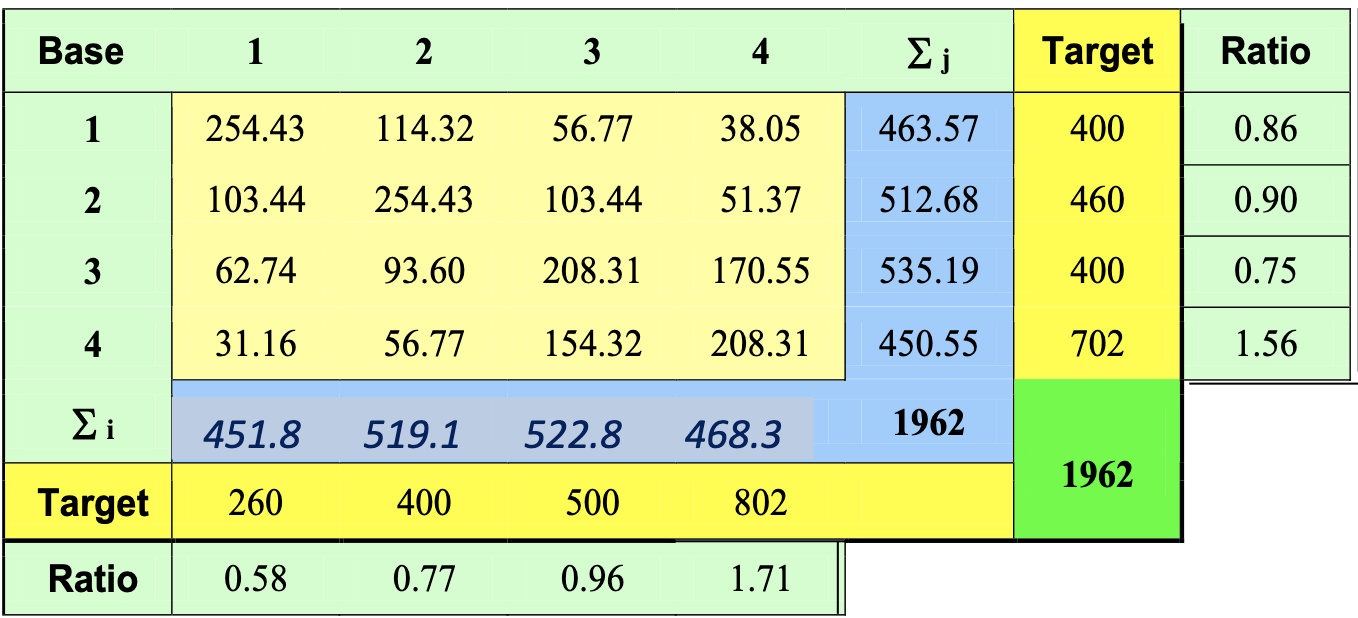
from this, the BPF method is applied and we get the following matrix (now every cell contains a value that represents the number of trips):
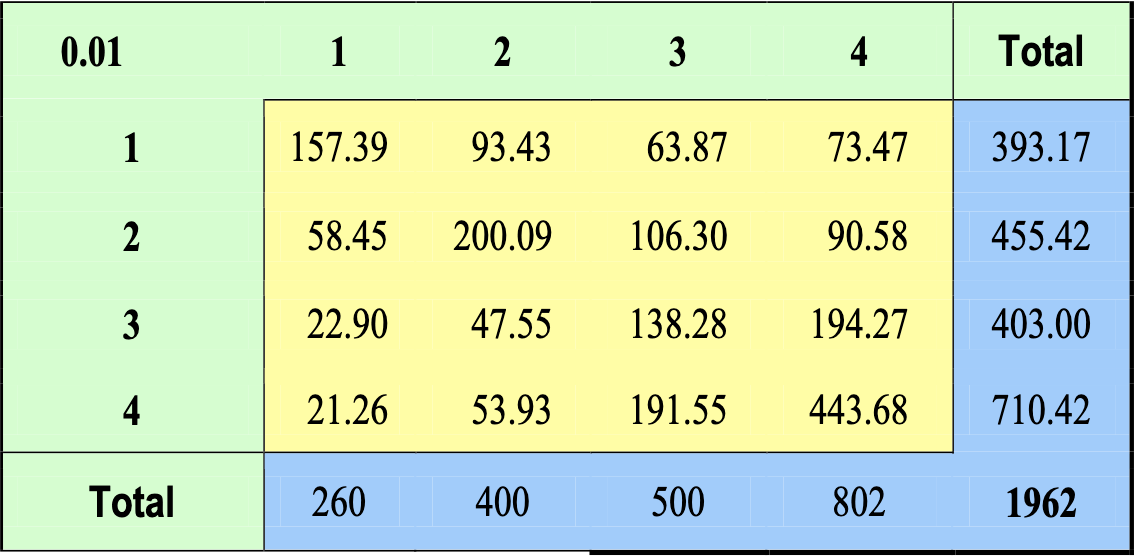
Entropy models
Entropy models are based on the law of entropy:
❗❗❗❗❗❗❗❗❗❗❗❗
❗❗❗ COMPLETARE ❗❗❗
❗❗❗❗❗❗❗❗❗❗❗❗
Hyman's method
When we #Apply a synthetic distribution models, we need to know the parameter of the cost functional
we can use Hyman's method to find the appropriate value of
To apply this method we need:
observed trip production observed trip attraction cost matrix Mean trip length - This is a parameter that is calculated from a smaller sample
Assumptions:
unknown - OD matrix can be obtained through #Doubly constrained growth factor - Biproportional Fitting (BPF)
As for other sections in this note, example numbers are shown in tables.
Let's assume we start from the following condition:

We have marginal totals but no
We have to start with some value of
Now we have all the information needed to apply the #Synthetic distribution models. We get the following matrix:
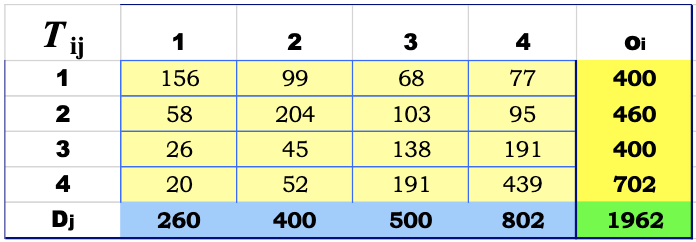
Let's now check the value of Mean Travel Time that we get from this:
The expected value of MTL is 10. They are too different, we need another iteration
Now we set
Calculate again the trip matrix as before and again
For the example used so far we get:

Let
Let
- Set
- Do nothing
- Set
- #Apply a synthetic distribution models
- If
go to next iteration, otherwise stop
- Set
- #Apply a synthetic distribution models
- If
go to next iteration, otherwise stop
- Set
- #Apply a synthetic distribution models
- If
repeat, otherwise stop