Confidence Interval
Confidence Interval
A confidence interval is the interval in which a population statistic is contained when estimated by a sample statistic.
Let
where
Let's suppose
as the area in the interval
In order to find this value it's important to use statistic tables. For the Standard Normal Distribution you can read more about them in Standard Normal Distribution#Statistical tables.
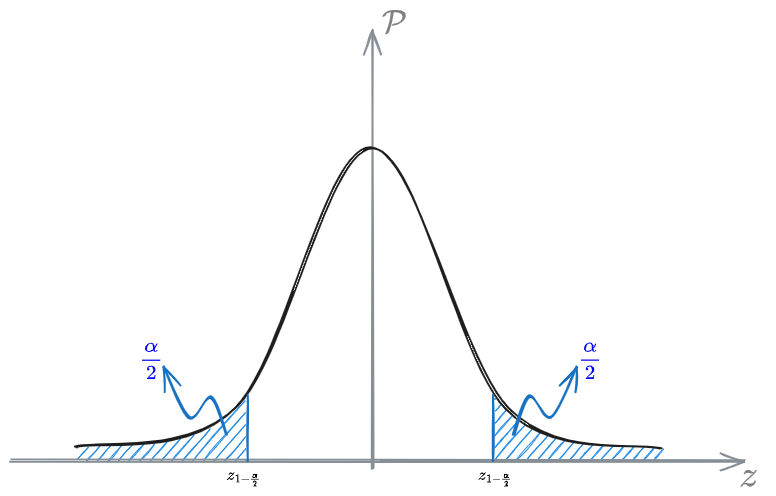
We use the Standard normal distribution since is well known. Then, we scale it according to a factor dependent on the variance of the variable we are interested in:
One particular variable of a population has a mean of
We want an estimate for the population mean with 95% confidence. This mean we want an
We are basically looking for the value:
that is the value such that the area under the density distribution is equal to 0.975.
From the probability table we can find out that such value is:
given a large number of observations.
Level of significance - The percentage is the Degree of confidence
We are assuming to know the variance of the population. This is clearly impossible. Actually, also the variance, as the mean, follows a random probability distribution (that can be proven to be a ???). For the porpuses we are usually interested in, we can simply use the sample variance (